先介绍下什么是协程:
协程,又称微线程,纤程,英文名Coroutine。协程的作用,是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行。
是不是有点没看懂,没事,我们下面会解释。要理解协程是什么,首先需要理解yield,这里简单介绍下,yield可以理解为生成器,yield item这行代码会产出一个值,提供给next(...)的调用方; 此外,还会作出让步,暂停执行生成器,让调用方继续工作,直到需要使用另一个值时再调用next()。调用方会从生成器中拉取值,但是在协程中,yield关键字一般是在表达式右边(如,data=yield),协程可以从调用方接收数据,也可以产出数据,下面看一个简单的例子:
>>> def simple_coroutine():
... print('coroutine start')
... x = yield
... print('coroutine recive:',x)
...
>>> my_co=simple_coroutine()
>>> my_co
<generator object simple_coroutine at 0x1085174f8>
>>> next(my_co)
coroutine start
>>> my_co.send(42)
coroutine recive: 42
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
其中x = yield就是精髓部分,意思是从客户端获取数据,产出None,因为yield关键字右边没有表达式,
而协程在创建完成之后,是没有启动的,没有在yield处暂停,所以需要调用next()函数,启动协程,在调用my_co.send(42)之后,协程定义体中的yield表达式会计算出42,现在协程恢复,一直运行到下一个yield表达式,或者终止,在最后,控制权流动到协程定义体的末尾,生成器抛出StopIteration异常。
协程有四个状态,如下: - 'GEN_CREATED' 等待开始执行。 - 'GEN_RUNNING' 解释器正在执行。 - 'GEN_SUSPENDED' 在 yield 表达式处暂停。 - 'GEN_CLOSED' 执行结束。
当前状态可以使用inspect.getgeneratorstate来确定,如下:
>>> import inspect
>>> inspect.getgeneratorstate(my_co)
'GEN_CLOSED'
这里再解释下next(my_co),如果在创建好协程对象之后,立即把None之外的值发送给它,会出现如下错误:
>>> my_co=simple_coroutine()
>>> my_co.send(42)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: can't send non-None value to a just-started generator
>>> my_co=simple_coroutine()
>>> my_co.send(None)
coroutine start
最先调用 next(my_co) 函数这一步通常称为“预激”(prime)协程(即,让协程向前执行到第一个 yield 表达式,准备好作为活跃的协程使用)。
再参考下面这个例子:
>>> def simple_coro2(a):
... print('-> Started: a =', a)
... b = yield a
... print('-> Received: b =', b)
... c = yield a + b
... print('-> Received: c =', c)
...
>>> my_coro2 = simple_coro2(14)
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(my_coro2)
'GEN_CREATED'
>>> next(my_coro2) # 协程执行到`b = yield a`处暂停,等待为b赋值,
-> Started: a = 14
14
>>> getgeneratorstate(my_coro2)
'GEN_SUSPENDED' #从状态也可以看到,当前是暂停状态。
>>> my_coro2.send(28) #将28发送到协程,计算yield表达式,并把结果绑定到b,产出a+b的值,然后暂停。
-> Received: b = 28
42
>>> my_coro2.send(99)
-> Received: c = 99
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
>>> getgeneratorstate(my_coro2)
'GEN_CLOSED'
simple_coro2的执行过程如下图所示:
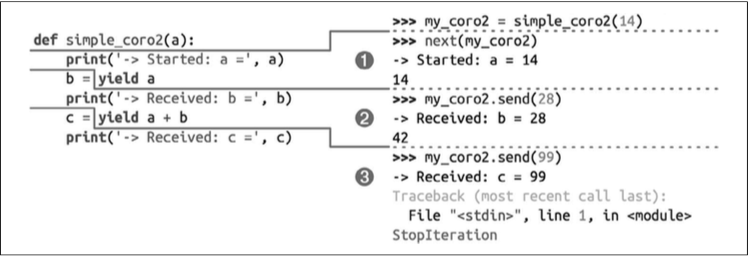 1. 调用
1. 调用next(my_coro2),打印第一个消息,然后执行yield a,产出数字 14。
2. 调用my_coro2.send(28),把28赋值给b,打印第二个消息,然后执行yield a + b,产
出数字 42。
3. 调用my_coro2.send(99),把 99 赋值给 c,打印第三个消息,协程终止。
说了这么多,我们为什么要用协程呢,下面我们再看看它的优势是什么: - 执行效率极高,因为子程序切换(函数)不是线程切换,由程序自身控制,没有切换线程的开销。所以与多线程相比,线程的数量越多,协程性能的优势越明显。 - 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁,因此执行效率高很多。
说明:协程可以处理IO密集型程序的效率问题,但是处理CPU密集型不是它的长处,如要充分发挥CPU利用率可以结合多进程+协程。
下面看最后一个例子,传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlparse
start_url = 'https://www.cnblogs.com'
trust_host = 'www.cnblogs.com'
ignore_path = []
history_urls = []
def parse_html(html):
soup = BeautifulSoup(html, "lxml")
print(soup.title)
links = soup.find_all('a', href=True)
return (a['href'] for a in links if a['href'])
def parse_url(url):
url = url.strip()
if url.find('#') >= 0:
url = url.split('#')[0]
if not url:
return None
if url.find('javascript:') >= 0:
return None
for f in ignore_path:
if f in url:
return None
if url.find('http') < 0:
url = start_url + url
return url
parse = urlparse(url)
if parse.hostname == trust_host:
return url
def consumer():
html = ''
while True:
url = yield html
if url:
print('[CONSUMER] Consuming %s...' % url)
rsp = requests.get(url)
html = rsp.content
def produce(c):
next(c)
def do_work(urls):
for u in urls:
if u not in history_urls:
history_urls.append(u)
print('[PRODUCER] Producing %s...' % u)
html = c.send(u)
results = parse_html(html)
work_urls = (x for x in map(parse_url, results) if x)
do_work(work_urls)
do_work([start_url])
c.close()
if __name__ == '__main__':
c = consumer()
produce(c)
print(len(history_urls))
首先consumer函数是一个generator,在开始执行之后:
1. 调用next(c)启动生成器;
2. 进入do_work,这是一个递归调用,其内部将url传递给consumer,由consumer来发出请求,获取到html信息,返回给produce,
3. produce解析html,获取url数据,继续生产url,
4. 当所有的url都在history_urls中,也就是说我们已经爬取了所有的url地址,结束递归调用
5. 调用c.close(),关闭consumer,整个过程结束。
可以看到,我们的整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
本文由 liangliangyy 原创,转载请注明出处。
qwert
import new 如何高亮
想请教您一个关于安全性的问题,如果有人利用代码不断地注册用户,那会不会影响真正在注册的用户呢?
博主好呢
嗯嗯你好.
来测试一哈
好吧